Abstract
Streaming visual transformers like StreamVGGT achieve strong 3D perception but suffer from unbounded growth of key–value (KV) memory, which limits scalability. We propose a training-free, inference-time token eviction policy that bounds memory by discarding redundant tokens while keeping the most informative ones. Our method uses significantly less memory with little to no drop in accuracy: on 7-Scenes with long sequences it reduces peak memory from 18.63 GB to 9.39 GB while accuracy and completeness drop by only 0.003. Under strict memory budgets, eviction enables denser frame sampling, which improves reconstruction accuracy compared to the baseline. Experiments across video depth estimation (Sintel, KITTI), 3D reconstruction (7-Scenes, NRGBD), and camera pose estimation (Sintel, TUM-dynamics) show that our approach closely matches StreamVGGT at a fraction of the memory and makes long-horizon streaming inference more practical.
Method
Our method manages the growing key–value (KV) cache of StreamVGGT by introducing a layer-wise token eviction framework. Each new frame produces tokens that are added to the cache; when the cache reaches its per-layer budget, we rank all tokens by their cumulative attention scores, normalized for exposure and sequence length. Tokens that receive little attention are evicted, while essential ones are preserved. This simple plug-and-play mechanism keeps memory bounded while maintaining the rich context needed for accurate 3D reconstruction.
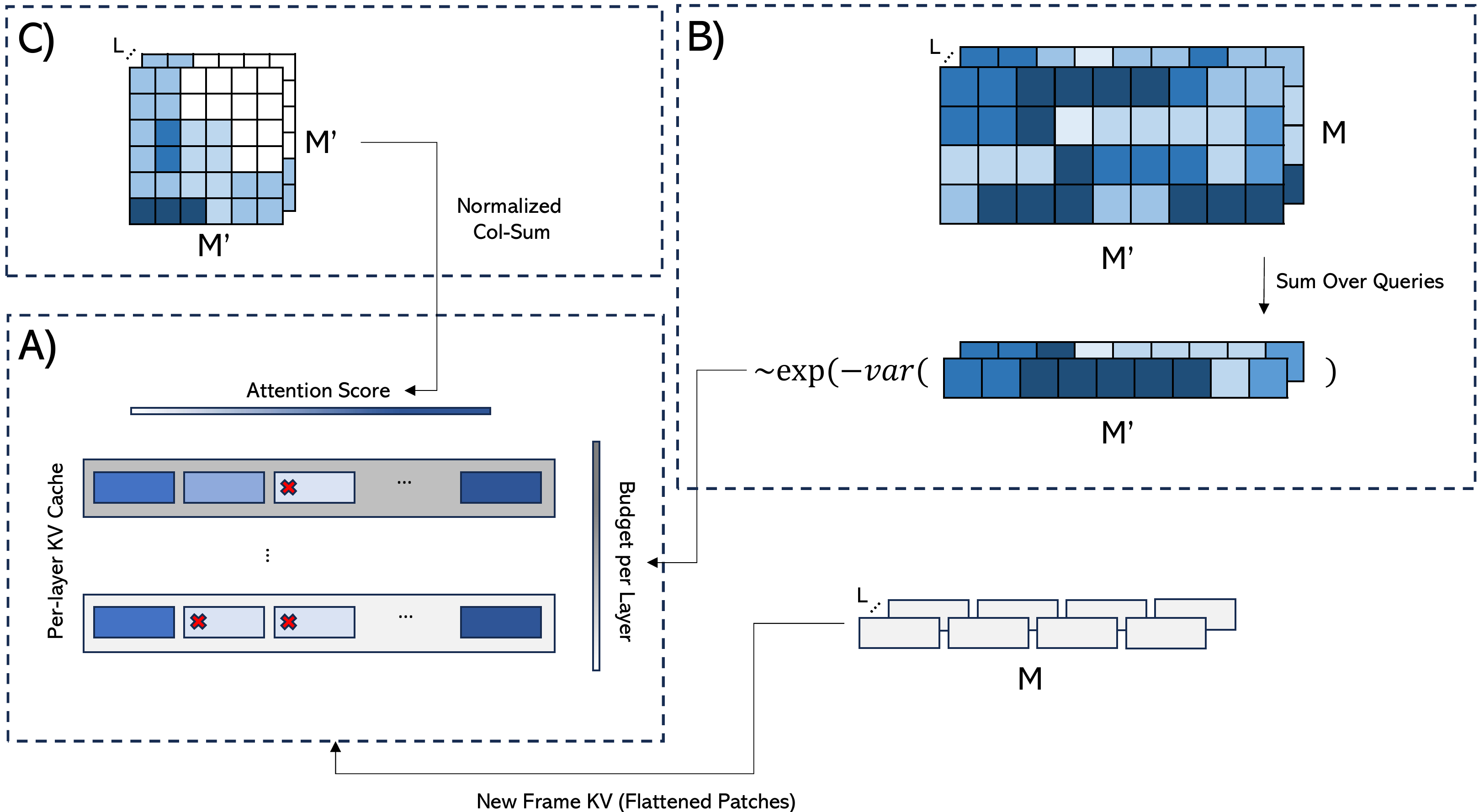
Select a layer to view the corresponding token eviction video for a smaple input.

Results Comparison
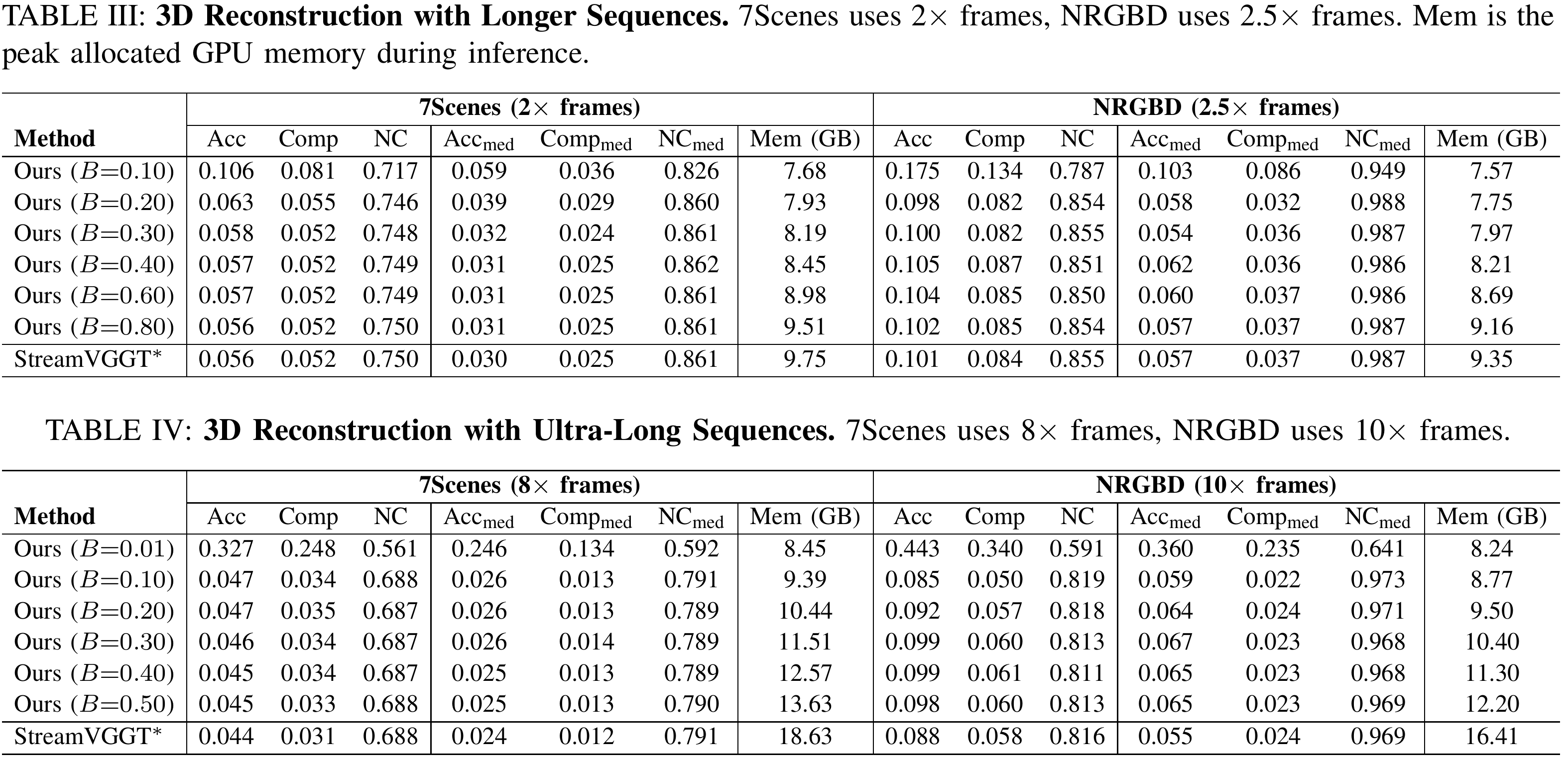
Quantitative comparison of Evict3R with baseline StreamVGGT across different datasets and metrics. Table III samples 6-10 frames for 7-Scenes and 5-10 frames for NRGBD. Table IV samples 24-40 frames for 7-Scenes and 20-40 frames for NRGBD. For ultra-long sequences (Table IV), StreamVGGT requires 16.41GB (NRGBD) and 18.63 GB (7Scenes), but our method achieves similar accuracy with nearly half the memory.
Layer-wise Eviction Videos
BibTeX
@misc{mahdi2025evict3rtrainingfreetokeneviction,
title={Evict3R: Training-Free Token Eviction for Memory-Bounded Streaming Visual Geometry Transformers},
author={Soroush Mahdi and Fardin Ayar and Ehsan Javanmardi and Manabu Tsukada and Mahdi Javanmardi},
year={2025},
eprint={2509.17650},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2509.17650},
}